Jsoup爬虫入门
粗略的了解一下Java的Jsoup爬虫入门
首先肯定是导包

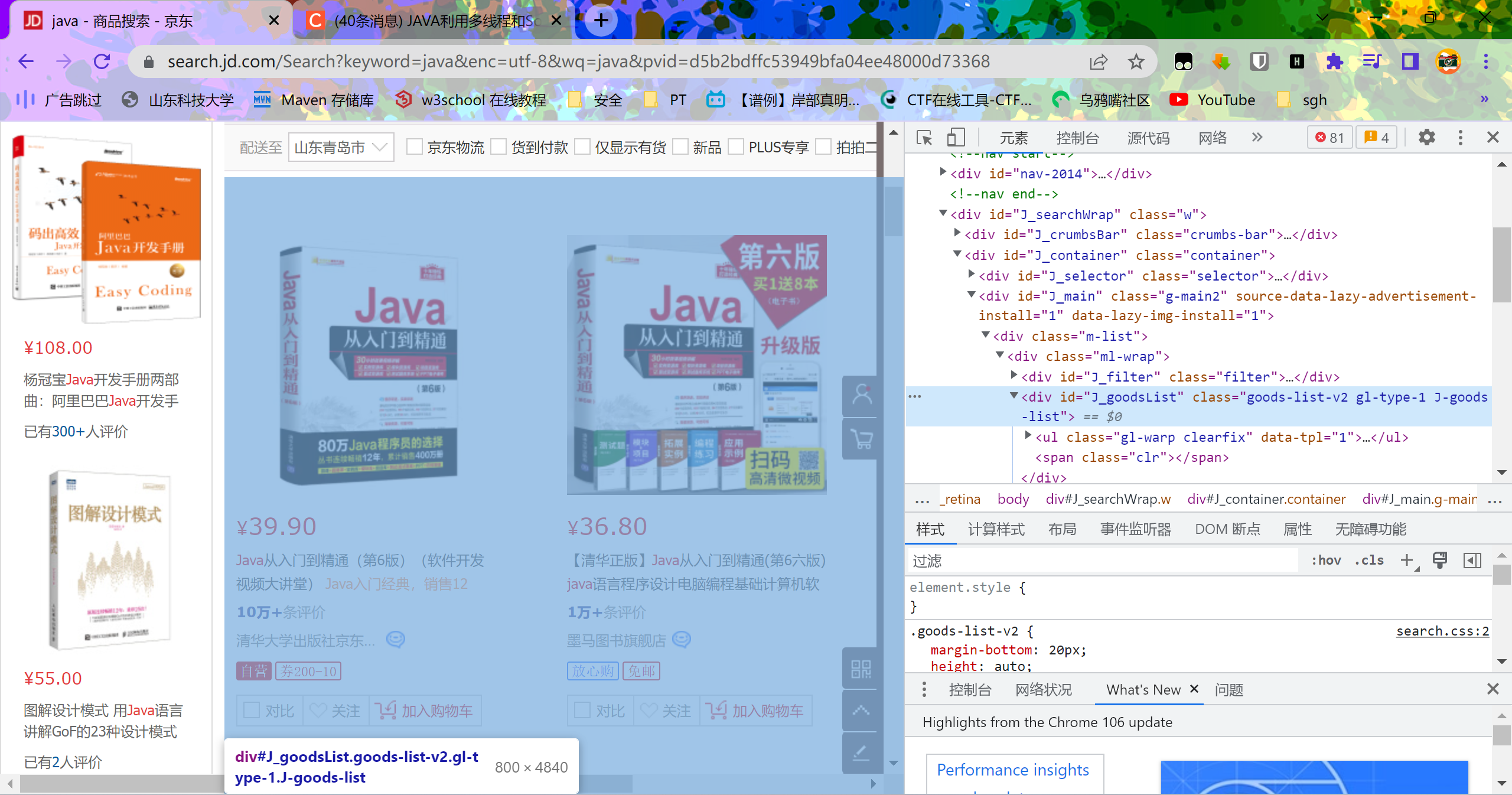
这次我们拿京东的搜索商品来举例,我们搜索java,然后观察地址栏的url
https://search.jd.com/Search?keyword=java,关键url就是这一段
首先了解一下jsoup的Document类,Document是一个装载html的文档类,即通过我们传入的url获取整个页面的html内容
然后我们看一下爬虫代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.URL;
public class jsoup {
public static void main(String[] args) throws IOException {
String url="https://search.jd.com/Search?keyword=java";
Document document = Jsoup.parse(new URL(url), 30000);
Element element=document.getElementById("J_goodsList");
Elements elements=element.getElementsByTag("li");
for(Element el:elements){
String price=el.getElementsByClass("p-price").eq(0).text();
String title=el.getElementsByClass("p-name").eq(0).text();
System.out.println("======================================");
System.out.println(price);
System.out.println(title);
}
}
}
|
通过前端代码找到自己需要的东西所对应的元素即可